# 分布式锁原理与设计
# 分布式锁的理解与实现
分布式锁,是一种跨进程的跨机器节点的互斥锁,它可以用来保证多机器节点对于共享资源访问的排他性。
我觉得分布式锁和线程锁本质上是一样的,线程锁的生命周期是单进程多线程,分布式锁的声明周期是多进程多机器节点。 在本质上,他们都需要满足锁的几个重要特性:
- 排他性,也就是说,同一时刻只能有一个节点去访问共享资源。
- 可重入性,允许一个已经获得锁的进程,在没有释放锁之前再次重新获得锁。
- 锁的获取、释放的方法
- 锁的失效机制,避免死锁的问题
所以,我认为,只要能够满足这些特性的技术组件都能够实现分布式锁。
关系型数据库,可以使用唯一约束来实现锁的排他性,如果要针对某个方法加锁,就可以创建一个表包含方法名称字段, 并且把方法名设置成唯一的约束。那抢占锁的逻辑就是:往表里面插入一条数据,如果已经有其他的线程获得了某个方法的锁, 那这个时候插入数据会失败,从而保证了互斥性。这种方式虽然简单啊,但是要实现比较完整的分布式锁, 还需要考虑重入性、锁失效机制、没抢占到锁的线程要实现阻塞等,就会比较麻烦。
Redis,它里面提供了SETNX命令可以实现锁的排他性,当key不存在就返回1,存在就返回0。然后还可以用expire命令设置锁的失效时间,从而避免死锁问题。 当然有可能存在锁过期了,但是业务逻辑还没执行完的情况。 所以这种情况,可以写一个定时任务对指定的key进行续期。 Redisson这个开源组件,就提供了分布式锁的封装实现,并且也内置了一个Watch Dog机制来对key做续期。
我认为Redis里面这种分布式锁设计已经能够解决99%的问题了,当然如果在Redis搭建了高可用集群的情况下出现主从切换导致key失效,这个问题也有可能造成 多个线程抢占到同一个锁资源的情况,所以Redis官方也提供了一个RedLock的解决办法,但是实现会相对复杂一些。
- 分布式锁应该是一个CP模型,而Redis是一个AP模型,所以在集群架构下由于数据的一致性问题导致极端情况下出现多个线程抢占到锁的情况很难避免。
那么基于CP模型又能实现分布式锁特性的组件,我认为可以选择Zookeeper或者etcd,
- 在数据一致性方面,zookeeper用到了zab协议来保证数据的一致性,etcd用到了raft算法来保证数据一致性。
- 在锁的互斥方面,zookeeper可以基于有序节点再结合Watch机制实现互斥和唤醒,etcd可以基于Prefix机制和Watch实现互斥和唤醒。
# 基于数据库的分布式锁
在分布式系统中,通常会使用共享的数据库或缓存系统作为数据存储。因此,要实现分布式锁,最简单的方式可能就是直接创建一张锁表, 然后通过操作该表中的数据来实现了。当我们要锁住某个方法或资源的时候,我们就在该表中增加一条记录,想要释放锁的时候就删除这条记录。
CREATE TABLE `methodLock` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`method_name` varchar(64) NOT NULL DEFAULT '' COMMENT '锁定的方法名’,
`desc` varchar(1024) NOT NULL DEFAULT '备注信息',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '保存数据时间,自动生成',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_method_name` (`method_name `) USING BTREE
)
ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';
当我们要锁住某个方法时,执行以下SQL:insert into methodLock(method_name,desc) values (‘method_name’,‘desc’)
因为我们对method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,
那么我们可以认为操作成功的那个线程获得了该方法的锁,可以执行具体内容。当方法执行完毕之后,想要释放锁的话,
需要执行以下sql:delete from methodLock where method_name ='method_name'
上面这种简单的实现有以下几个问题:
- 这把锁依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
- 这把锁没有失效时间,一旦解决操作失败,就会导致记录一直在数据库中,其他线程无法在获得锁。
- 这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁的操作。
- 这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据库表中数据已经存在了。
其它方式解决上面的问题:
- 数据库是单点?那就搞两个数据库,数据库之前双向同步,一旦挂掉快速切换到备库上。
- 没有失效时间?可以做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。
- 非阻塞?可以写一个while循环,直到insert成功再返回成功。
- 非重入?可以在数据库表中加一个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库中可以查到的话,就直接把锁分配给它即可。
优点:实现简单,易于控制,能轻松处理一些容易发生死锁或锁竞争问题。 缺点:数据库锁会引起严重的性能瓶颈,特别是当锁的数量特别大时。
# 基于数据库表做乐观锁
使用版本号时,可以在数据初始化时指定一个版本号,每次对数据的更新操作都对版本号执行+1操作。并判断当前版本号是不是该数据的最新的版本号。
需要注意的是,乐观锁机制往往基于系统中数据存储逻辑,因此也具备一定的局限性。由于乐观锁机制是在我们的系统中实现的, 对于来自外部系统的用户数据更新操作不受我们系统的控制,因此可能会造成脏数据被更新到数据库中。在系统设计阶段,我们应该充分考虑到这些情况, 并进行相应的调整(如将乐观锁策略在数据库存储过程中实现,对外只开放基于此存储过程的数据更新途径,而不是将数据库表直接对外公开)。
# 基于数据库表做悲观锁
除了可以通过增删操作数据库表中的记录以外,还可以借助数据库中自带的锁来实现分布式锁。 我们还用上面创建的数据库表,可以通过数据库的排它锁来实现分布式锁。基于MySQL的InnoDB引擎,可以使用以下方法来实现加锁操作:
public boolean lock(){
Connection.setAutoCommit(false);
while (true) {
try {
result = select * from MethodLock where methodName = 'xxxx' for update;
if (result == null) {
return false;
}
} catch (Exception e) {
}
sleep(1000);
}
returnType false;
}
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁(InnoDB引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁, 否则会使用表级锁。这里我们希望使用行级锁,就要给method_name添加索引,值得注意的是,这个索引一定要创建成唯一索引, 否则会出现多个重载方法之间无法同时被访问的问题。重载方法的话建议把参数类型也加上)。当某条记录被加上排他锁之后, 其他线程无法再在该行记录上增加排他锁。
我们可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过以下方法解锁: 通过connection.commit()操作来释放锁。
public void unlock(){
connection.commit();
}
这里还可能存在另外一个问题,虽然我们对method_name 使用了唯一索引,并且显示使用for update来使用行级锁。但是,MySql会对查询进行优化, 即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 认为全表扫效率更高, 比如对一些很小的表,它就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。如果发生这种情况就悲剧了。
还有一个问题,就是我们要使用排他锁来进行分布式锁的lock,那么一个排他锁长时间不提交,就会占用数据库连接。一旦类似的连接变得多了,就可能把数据库连接池撑爆。
这种方法可以有效的解决上面提到的无法释放锁和阻塞锁的问题: 1、阻塞锁?for update语句会在执行成功后立即返回,在执行失败时一直处于阻塞状态,直到成功。 2、锁定之后服务宕机,无法释放?使用这种方式,服务宕机之后数据库会自己把锁释放掉。
但是还是无法解决数据库单点和可重入的问题。
- 优点:直接借助数据库容易理解;
- 缺点:1、会有各种各样的问题,在解决问题的过程中会使整个方案变的越来越复杂。2、操作数据库需要一定的开销,性能问题需要考虑。
# 基于Redis的分布式锁
Redis是一种高性能Key-Value数据库,使用Redis实现分布式锁是非常方便的。分布式锁的思路与基于数据库实现相同, 使用Redis的SETNX(SET if Not eXists)命令来创建一个锁,这个键实际上就是用于实现分布式锁的一个标志。 只有当该键不存在时,才会执行SETNX命令创建一个键值对,并把值设置为持有锁的线程的ID,其他线程在尝试获取这个锁时, 都会失败。进程完成操作后,需要删除这个键值对,释放锁。
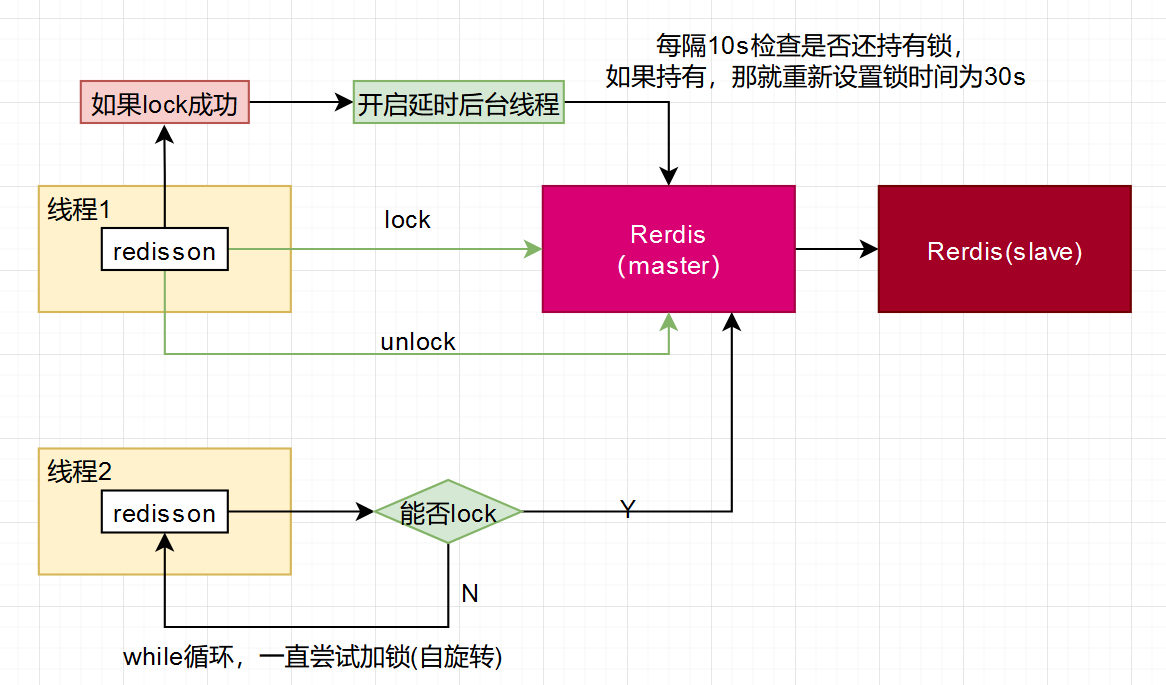
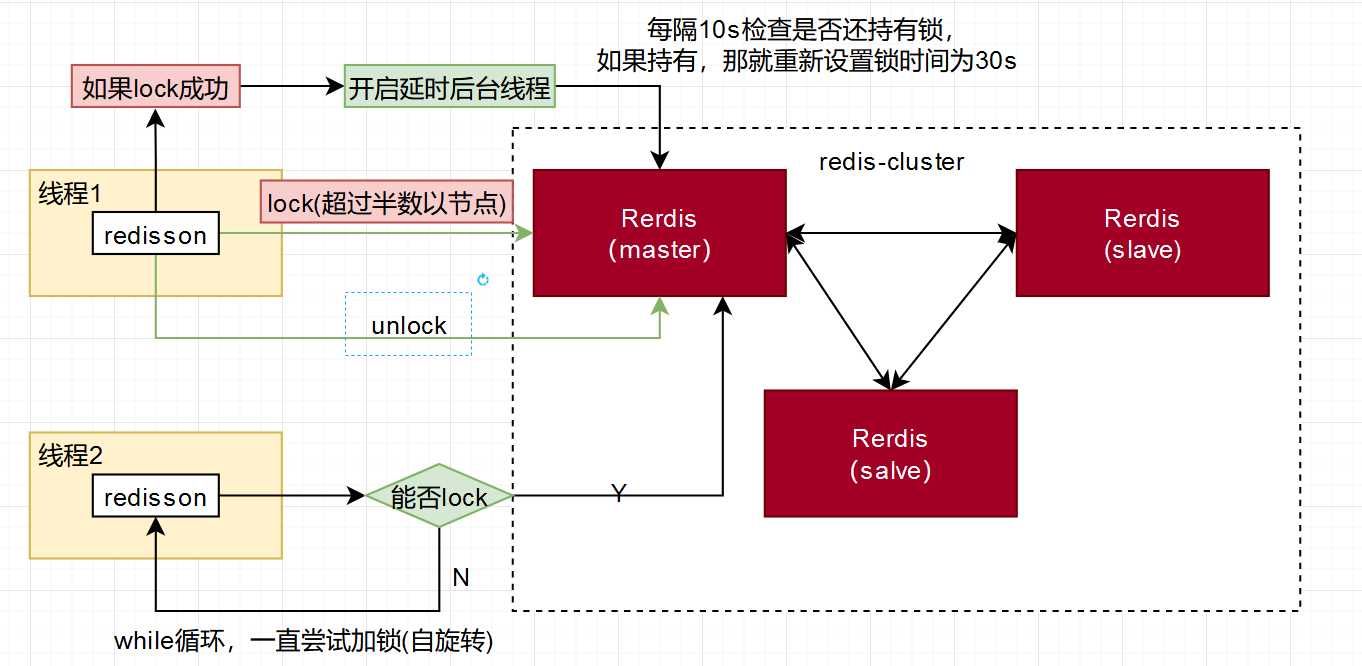
优点:Redis提供了高效的获取锁和释放锁的操作,不需要像使用数据库那样频繁读写数据库,使用起来非常高效。 缺点:会存在死锁问题,需要谨慎处理。当某个进程获取锁之后,由于某些原因没有来得及释放锁,可能导致其他进程无法获取该锁。
# 基于zookeeper的分布式锁
ZooKeeper是一种提供的分布式服务框架,用于协调各个进程之间的通信。利用ZooKeeper提供的节点同步功能,可以很容易地实现分布式锁。 具体实现方法是,设计一个锁节点,进程在想获取锁时,在锁节点下面创建一个序号,然后和其它序号进行比较, 如果自己的序号是最小的,则获取到锁;否则,等待比自己序号小的节点完成之后再重试。
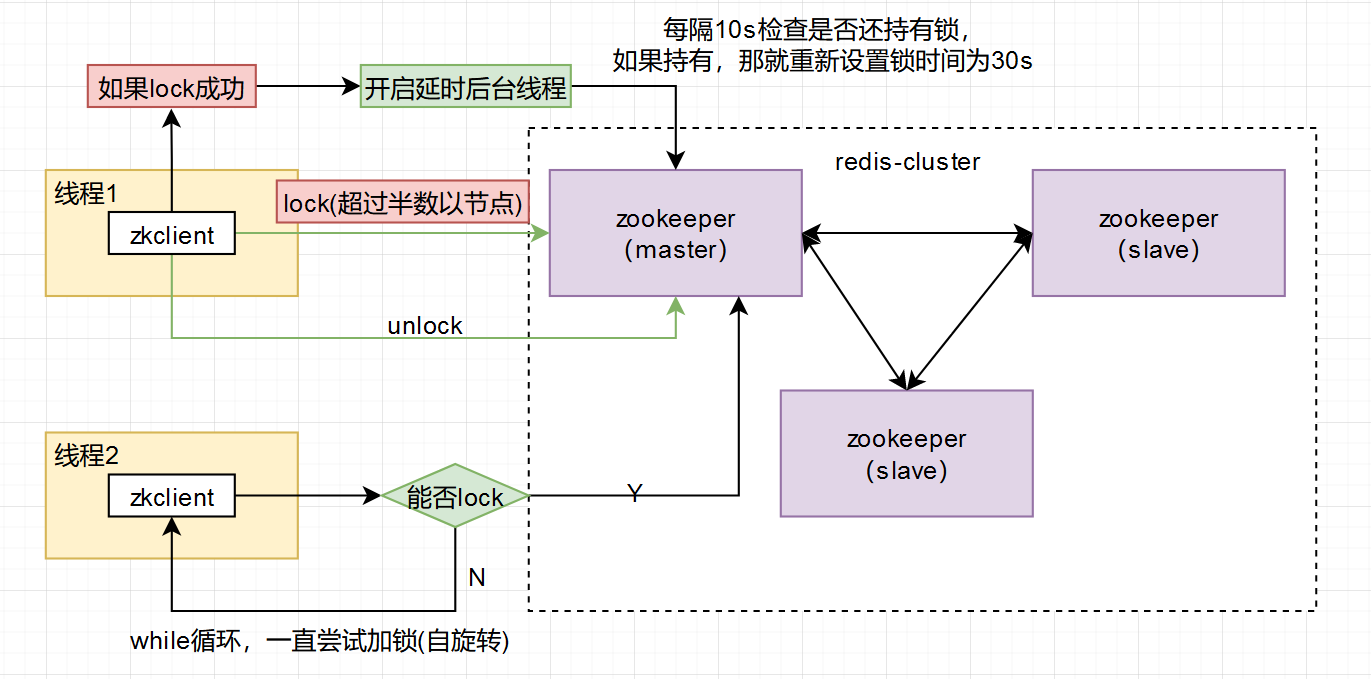
优点: 基于ZooKeeper的实现,具有良好的顺序性,能够很好地避免死锁和竞争问题,而且也具备高可用性。 缺点: 实施代价较高,需要依赖Zookeeper,需要准备一个独立的ZooKeeper集群以维护状态。
← 分布式ID原理与设计 分布式事务原理与设计 →