# SpringCloud面试问题
# Eureka server数据同步原理
Eureka是一个服务注册中心,在Eureka的设计里面,为了保证Eureka的高可用性,提供了集群的部署方式。 Eureka的集群部署采用的是两两相互注册的方式来实现,也就是说每个Eureka Server节点都需要发现集群中的其他节点并建立连接, 然后通过心跳的方式来维持这个连接的状态。Eureka Server集群节点之间的数据同步方式非常简单粗暴,使用的是对等复制的方式来实现数据同步。 也就是说,在Eureka Server集群中,不存在所谓主从节点,任何一个节点都可以接收或者写入数据。一旦集群中的任意一个节点接收到了数据的变更,就直接同步到其他节点上。
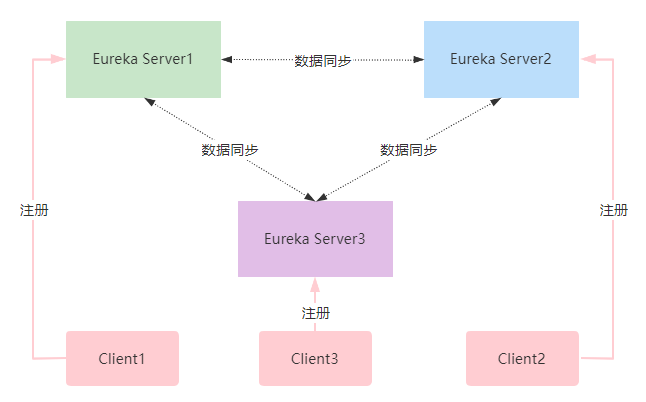
这种无中心化节点的数据同步,需要考虑到一个数据同步死循环的问题,也就是需要区分Eureka Server收到的数据是属于客户端传递来的数据还是集群中其他节点发过来的同步数据。 Eureka使用了一个时间戳的标记来实现类似于数据的版本号来解决这个问题。另外,从Eureka的数据同步方案来看,Eureka集群采用的是AP模型,也就是只提供高可用保障,而不提供数据强一致性保障。 之所以采用AP,我认为注册中心它只是维护服务之间的通信地址,数据是否一致对于服务之间的通信影响并不大。而注册中心对Eureka的高可用性要求会比较高,不能出现因为Eureka的故障导致服务之间无法通信的问题。
Eureka虽然闭源了,但是在国内依然使用较为广泛。当然有些公司逐步迁移到了Nacos上面,但是Eureka的整个框架设计上还是有非常多值得我们学习的思想。多级缓存设计、集群之间的数据同步方案、多区域隔离以及就近访问的设计等等。
← spring面试问题 设计模式面试问题 →